“Bringing MLtwist to Google Cloud Marketplace will help customers quickly deploy, manage, and grow its platform on Google Cloud’s trusted, global infrastructure”

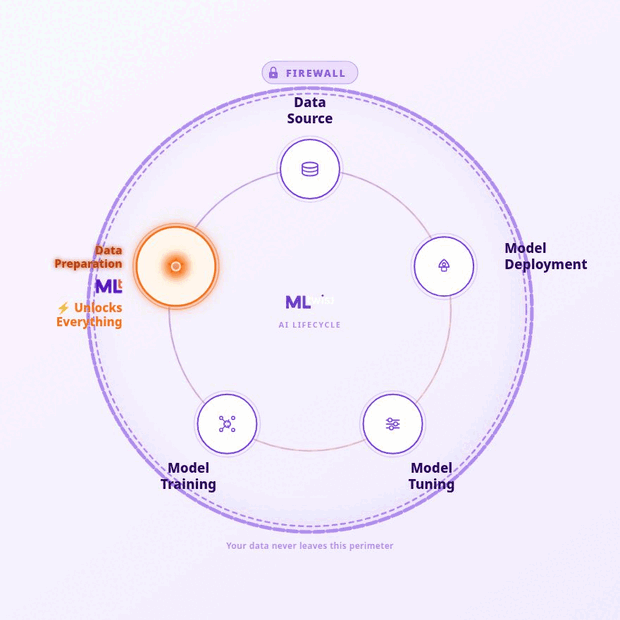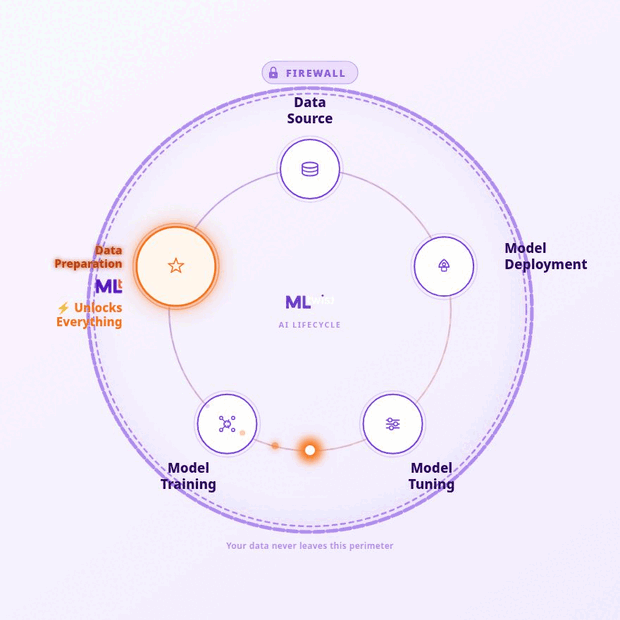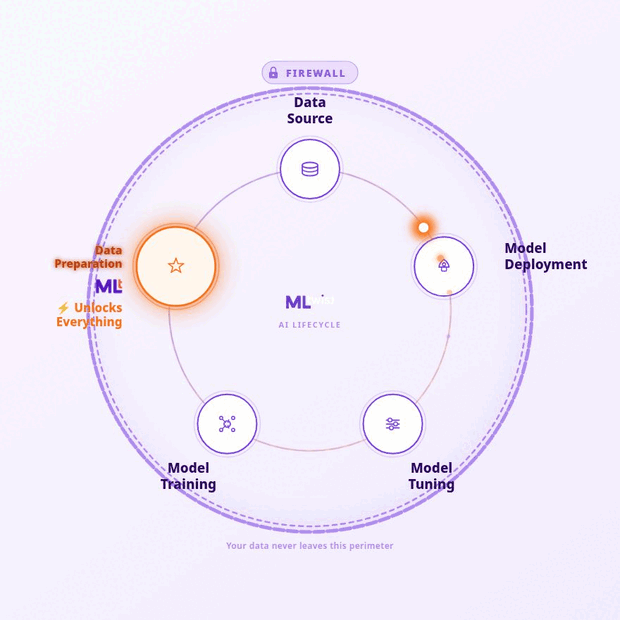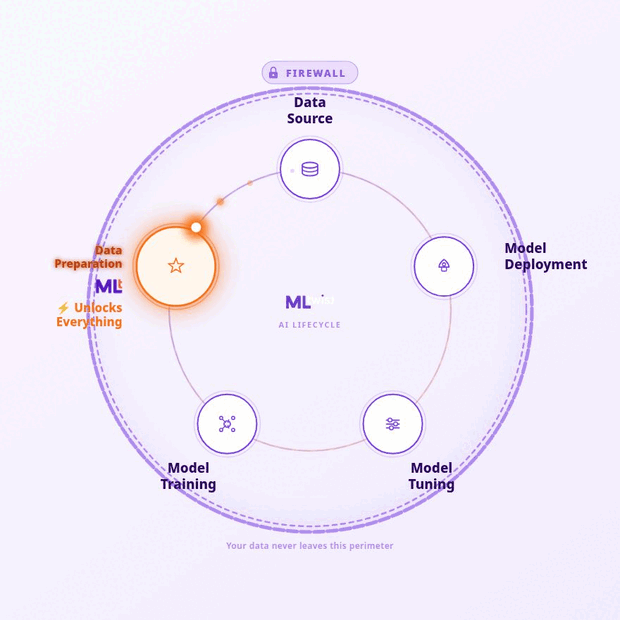
“With the addition of MLtwist to our offerings, we help Government agencies prepare data for AI at scale in a secure environment and ensure innovation meets the Public Sector head-on”

“Thanks to MLtwist’s AI data pipelines, we were able to reinvest 50% of our data science spend to increase model performance, while the labeling quality beats any existing open source or commercial solutions we have tried.