02
Apr

In the fast-evolving insurtech landscape, efficiency and accuracy are paramount. One of MLtwist’s recent successes involved partnering with an insurtech company to automate the extraction, labeling, and management of unstructured text data from various documents, including contracts, emails, and repair demand letters. The goal was to significantly improve processing time while maintaining high accuracy tagging and reducing costs.
Insurtech companies are relying more and more on AI and machine learning models to process the unstructured data and extract insights, automate decision-making, and enhance risk assessment.
One Insurtech company that focuses on streamlining the communication and claims process between law firms and insurance carriers reached out to MLtwist. Their primary goal is to reduce administrative tasks, eliminate unnecessary back-and-forth interactions, and minimize stalemates. This approach aims to save both parties money, reduce errors, and facilitate more efficient and fair settlements.
To achieve this, they leverage artificial intelligence to automate and standardize administrative tasks, enhancing the efficiency of injury claim settlements. By bridging the communication gap between plaintiff firms and insurance carriers, this company seeks to expedite the settlement process, ultimately benefiting all parties involved.
MLtwist provided an AI-powered solution that automated the extraction, labeling, and management of unstructured text data, drastically reducing processing time while maintaining high accuracy. Here’s how it changed the game.
Insurance companies deal with vast amounts of unstructured text data from different sources and formats, such as scanned documents (PDFs) and exported files (DOCX). Extracting relevant information manually from these documents was a slow, costly, and error-prone process. The insurtech company needed an AI-driven solution capable of efficiently identifying and extracting 13 key data fields with high accuracy to accelerate decision-making and claims processing.
The deployment of MLtwist’s technology led to significant operational improvements:
By eliminating bottlenecks, MLtwist helped this insurtech scale more efficiently and serve customers faster.
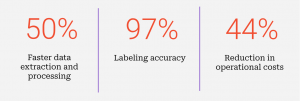
Processing unstructured data has long been a pain point for insurtech companies, slowing down claims treatment. By eliminating manual bottlenecks, MLtwist helps these companies process information faster, cut costs, and make better decisions by turning messy documents into structured, actionable data in real time. As the industry shifts toward AI-driven solutions, MLtwist is delivering real, measurable improvements—helping insurers move at the speed of their customers.